seo-audit — 基本 SEO 審核
一種輕量級 SEO 代理技能,專為快速、預設的單頁 SEO 審核而設計。由 OpenClaw 提供支援。適用於首次頁面檢查或需要快速評估而無需全面技術深度時。
何時使用此技能
在以下情況下使用 seo-audit:
- 使用者說:「審核此頁面」、「檢查 SEO」、「分析我的 URL」、「快速 SEO 檢查」、「我的頁面有什麼問題」
- 未要求特定深度 — 這是預設的入口點
- 使用者需要快速、易讀的摘要,而不是全面的技術分析
如果使用者需要更深入的內容,請升級到 seo-audit-full:
**提示:**對於深入的技術審核、進階頁面 SEO 或完整報告,請使用
seo-audit-full技能。
預期輸入
| 輸入 | 必填 | 備註 |
|---|---|---|
| 頁面 URL | 是 | 要審核的頁面 |
| 原始 HTML 或頁面內容 | 可選 | 啟用更精確的頁面分析 |
| GSC / 分析數據 | 可選 | 基本審核不需要 |
如果只提供了 URL,並且沒有可用的原始碼或爬蟲數據,請明確說明:
**限制:**此審核僅基於可見頁面內容和公開可用的信號。此審核無法獲取原始碼、GSC 數據、爬蟲日誌和性能指標。
輸出
透過填寫 assets/report-template.html 中的模板,生成一份 基本 SEO 審核報告, 然後將其保存到檔案中 — 切勿將原始 HTML 列印到終端機。
檔案命名: reports/<hostname>-<slug>-audit.html
https://example.com/blog/best-tools → reports/example-com-blog-best-tools-audit.html
https://example.com/ → reports/example-com-audit.html
保存後,告訴使用者:
✅ 報告已保存 → reports/example-com-audit.html
現在打開嗎?(是 / 否)
如果是 → 運行:open reports/example-com-audit.html
模板佔位符 — 獨立填寫每個:
| 佔位符 | 內容 |
|---|---|
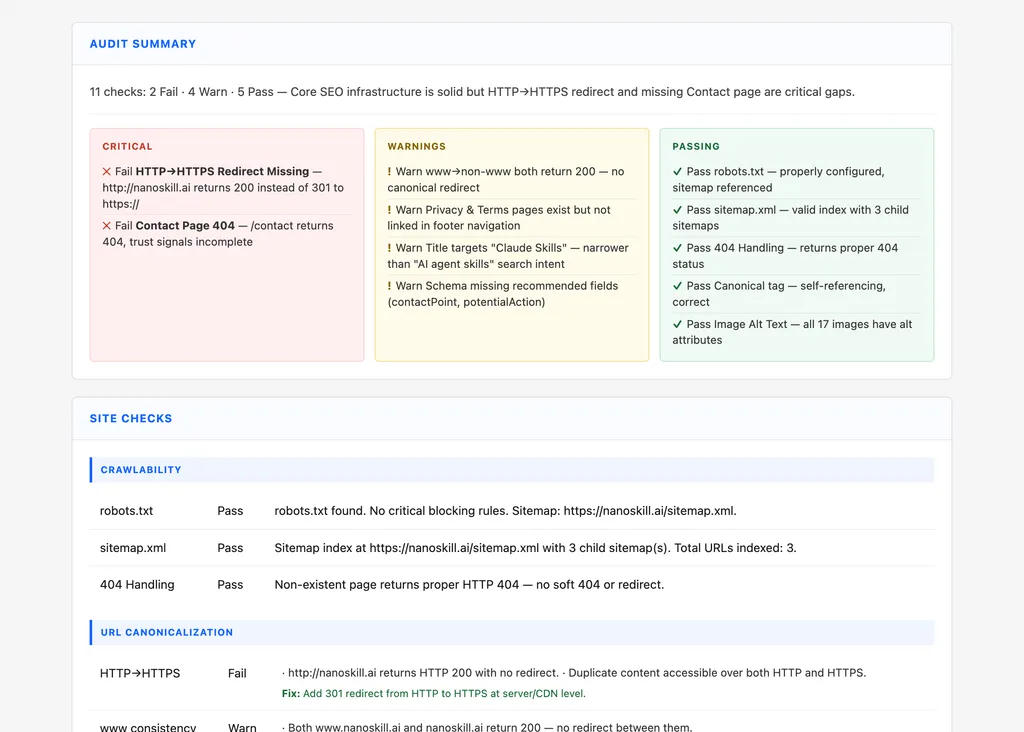
{{summary_verdict}} | 一句話:總共運行了多少檢查,多少失敗/警告/通過 |
{{summary_critical_html}} | 每個關鍵(失敗)項目的 <li>,或 <li class="summary-empty">無</li> |
{{summary_warnings_html}} | 每個警告項目的 <li>,或 <li class="summary-empty">無</li> |
{{summary_passing_html}} | 每個通過檢查的 <li>,或 <li class="summary-empty">無</li> |
腳本
在撰寫任何發現之前運行這些腳本。它們輸出結構化的 JSON — 直接使用 JSON 作為證據;不要手動重新獲取相同的 URL。
依賴項: pip install requests (HTML 解析使用 Python 標準庫)
# 步驟 1:網站級別檢查 (robots.txt + sitemap.xml)
python scripts/check-site.py https://example.com
# 步驟 2:頁面級別檢查 (H1、標題、元描述、規範)
python scripts/check-page.py https://example.com
# 帶有主要關鍵字(推薦 — 啟用 H1 關鍵字存在檢查)
python scripts/check-page.py https://example.com --keyword "running shoes"
# 可選:獲取原始頁面 HTML 以進行進一步檢查
python scripts/fetch-page.py https://example.com --output page.html
# 步驟 3:JSON-LD 結構驗證
python scripts/check-schema.py https://example.com
# 或從先前獲取的 HTML (避免重複獲取):
python scripts/check-schema.py --file page.html
每個腳本以代碼 0 (全部通過/警告) 或 1 (任何失敗/錯誤) 退出。
嚴格範圍 — 不要添加任何未列出的檢查。沒有例外。
允許的網站級別檢查 (在 {{site_checks_html}} 中):
- robots.txt · sitemap.xml · 404 處理 · URL 規範化 · i18n / hreflang
允許的 E-E-A-T 檢查 (在 {{eeat_checks_html}} 中):
- 關於我們 · 聯絡我們 · 隱私政策 · 服務條款 · 媒體/合作夥伴 (僅當存在時)
允許的頁面級別檢查 (在 {{page_checks_html}} 中),以這個確切順序輸出:
URL Slug · 標題標籤 · 元描述 · H1 標籤 · 規範標籤 · 圖片替代文字 · 字數 · 關鍵字佈局 · 標題結構 · 內部連結 · 結構化數據 (JSON-LD)
圖片替代文字邏輯:
- 從靜態 HTML 解析
<img>標籤 - 通過:所有圖片都有非空的 alt (裝飾性圖片帶有 alt="" 也可以)
- 警告:任何內容圖片缺少 alt 屬性
- 未驗證 (status-info):靜態 HTML 中未找到圖片 → 可能由 JS 渲染,無法驗證
⛔ 硬性規定 — 僅輸出 report-template.html 中定義的檢查行。 如果某項檢查不在上述允許列表中,請勿輸出 — 即使您發現了問題也不行。 沒有例外。沒有「額外」檢查。沒有即興發揮。 模板是唯一的真相來源。將其視為嚴格的白名單。
仍然禁止 (屬於 seo-audit-full):OG 標籤 · Twitter Card · 社交標籤 · 頁面權重 · 核心網頁指標 · Robots Meta
如何使用 JSON 輸出:
- 將每個欄位的
status→pass/warn/fail/error直接映射到報告檢查表 - 使用每個欄位的
detail字串作為發現中證據行的起點 - 除非您有額外的可觀察證據,否則不要與腳本輸出矛盾
- 在
{{site_checks_html}}內部使用<div class="subsection-label">標籤</div>分隔檢查組:可爬行性·URL 規範化·i18n / hreflang·結構化數據 (JSON-LD)以及在{{eeat_checks_html}}之前使用<div class="subsection-label">E-E-A-T 信任頁面</div>
LLM 審查 — 當 llm_review_required: true 時強制執行:
腳本會標記需要語義或品質判斷但無法執行的欄位。
切勿讓 llm_review_required: true 未解決 — 始終做出明確的判斷。
H1 — 當 keyword_match == "partial" 時觸發:
h1_text : (來自 h1.values[0])
keyword : (傳遞給腳本的 --keyword)
判斷:此 H1 是否語義上涵蓋了關鍵字的搜索意圖?
- 考慮同義詞、自然變體、主題覆蓋範圍
- 是 → 降級為「通過」,註明變體
- 否 → 保持「警告」或升級為「失敗」,解釋差距
標題 — 當 keyword_match == "partial" 或 keyword_position != "start" 時觸發:
title : (來自 title.value)
keyword : (傳遞的 --keyword)
判斷:
1. 標題是否語義上涵蓋了關鍵字的搜索意圖?
2. 標題是否語法正確且自然易讀?
3. 關鍵字位置 — 根據頁面類型應用不同標準:
- 首頁:品牌 + 核心關鍵字是正確的 (例如「Acme | AI 工作流程自動化」)
不要將品牌優先標記為問題。
- 內頁:核心關鍵字應領先 (例如「適用於團隊的 AI 工作流程自動化 — Acme」)
如果關鍵字無故埋在標題中間,則標記。
重要 — 不要將這些標記為負面:
- 年份 (例如「2026」) → 表示新鮮度,提高點擊率 — 除非頁面是明確的常青內容,否則將其視為正面,否則日期會損害壽命。
- 數字 (例如「5 個最佳」、「前 10 名」、「3 個步驟」) → 設定明確的期望,
在點擊率方面始終優於非數字標題 — 始終視為優點。
- 特定限定詞 (「開源」、「自託管」、「免費」) → 縮小意圖
並吸引更高品質的點擊 — 不要懲罰。
URL Slug — 當 keyword_match != "full" 或 is_homepage == false 時觸發:
slug : (來自 url_slug.slug)
keyword : (傳遞的 --keyword)
判斷:
1. slug 是否包含主要關鍵字或自然變體?
2. 路徑層次結構是否邏輯?(/category/keyword 是理想的)
3. 是否簡潔且易於人類閱讀?
首頁 (is_homepage: true):跳過 — 無需判斷。
元描述 — 當內容存在時始終觸發:
meta_description : (來自 meta_description.value)
keyword : (傳遞的 --keyword)
判斷所有四項:
1. 完整的句子?(1-2 句,無片段)
2. 提及具體結果 — 而非模糊的廢話?
好:「使用 AI 驅動的模板將設計時間縮短 60%」
壞:「滿足您所有設計需求的最佳工具」
3. 關鍵字或自然同義詞使用一次 — 而非堆砌?
4. 比典型競爭對手寫的更具體?
重要 — 不要將這些標記為負面:
- 年份 (例如「2026」) → 表示新鮮度,提高時間敏感查詢的點擊率。
僅當頁面是明確的常青內容,且日期會造成損害時,才註明年份。
- 數字 (例如「5 個最佳」、「3 個步驟」) → 具體性強,點擊率信號強。
- 結尾的「等等。」 → 最多是次要的風格註釋,絕不是警告或失敗。
推薦工作流程
請按照以下步驟依序執行:
-
確認範圍 — 確認這是基本審核;註明任何缺失的數據
-
推斷主要關鍵字 — 使用
fetch-page.py獲取頁面,然後確定主要關鍵字:- 如果使用者明確提供了關鍵字 → 直接使用它
- 如果沒有 → 閱讀頁面 H1、標題和第一段,然後推斷出最有可能的單個目標關鍵字詞組 (搜索者會輸入什麼來找到此頁面?)
- 在運行檢查之前明確說明推斷出的關鍵字:
「推斷出的主要關鍵字:開源 claude 替代方案」
-
運行
check-site.py— 解析 JSON 輸出以獲取 robots、sitemap、404 處理和 URL 規範化**404 檢查:**獲取
<origin>/this-page-definitely-does-not-exist-seo-audit-check- 返回 404 → 通過 · 返回 200 (軟 404) → 失敗 · 返回 301 到首頁 → 警告
URL 規範化檢查 (每個都是一個單獨的子檢查):
- **HTTP→HTTPS:**獲取
http://<host>— 必須 301 到https://。返回 200 → 失敗。 - **www 一致性:**同時獲取
https://www.<host>和https://<host>— 其中一個必須 301 到另一個。兩者都返回 200 → 警告。 - **尾部斜線:**比較實際提供的 URL 與頁面上的規範標籤。不匹配 → 警告。
- **規範匹配:**規範標籤 href 必須與所有重定向後的最終 URL 完全匹配。不匹配 → 警告。
-
E-E-A-T 基礎設施檢查 — 對於下面的每個信任頁面,檢查兩個層次:
- **層次 1 — 存在:**獲取 URL,檢查 HTTP 狀態 (200 = 存在,404/重定向 = 缺失)
- **層次 2 — 可達:**獲取首頁 HTML,檢查頁腳或導航是否包含指向此頁面的連結
頁面 必填 關於我們 是 聯絡我們 是 隱私政策 是 服務條款 是 媒體 / 合作夥伴 否 — 僅當存在時才包含 狀態規則:
- 頁面缺失 (非 200) → 失敗
- 頁面存在但未在頁腳/導航中連結 → 警告
- 頁面存在並在頁腳/導航中連結 → 通過
- 可選頁面缺失 → 跳過,不包含該行
-
運行
check-page.py --keyword "<inferred_keyword>"— 解析 JSON 輸出以獲取 H1、標題、 元描述、規範和 URL slug -
i18n / hreflang 檢查 — 僅當頁面包含 hreflang 標籤或
<html lang>表明多語言時才運行:- 如果未找到 hreflang 標籤且網站顯示為單語言,則完全跳過 (不適用)
- 如果存在 hreflang 標籤,請檢查:
- **互惠對稱:**每個引用的 URL 都必須連結回所有其他變體 — 任何斷開的連結 = 失敗
- **語言代碼:**必須是有效的 BCP 47 (例如
zh-CN而不是zh,en-US而不是en-us) — 錯誤代碼 = 警告 - **x-default:**應存在於語言選擇器或後備頁面 — 缺失 = 警告
- **html[lang] 屬性:**必須與頁面的主要 hreflang 匹配 — 不匹配 = 警告
- **URL 結構:**推薦模式 — 預設語言 (通常是
en) 在根目錄下沒有前綴, 其他語言在子路徑下 (/zh/、/es/)。/page(en) +/zh/page+/es/page→ 通過/en/page+/zh/page→ 警告 (en 前綴是多餘的,浪費爬行深度)- 僅當模式明顯不一致或 en 被不必要地加上前綴時才標記
-
運行
check-schema.py— 解析 JSON 輸出以獲取結構類型和欄位驗證python scripts/check-schema.py https://example.com # 或從先前獲取的 HTML: python scripts/check-schema.py --file page.html腳本提取 JSON-LD 區塊,根據 Schema.org 規範驗證
@type和必填欄位。llm_review_required: true始終設置 — 確認inferred_page_type與實際頁面內容匹配。頁面類型 → 預期
@type參考:頁面類型 預期 @type 最少必填欄位 首頁 WebSite + Organization name, url, logo 部落格 / 文章 Article 或 BlogPosting headline, datePublished, author, image 產品 Product name, image, offers (price, priceCurrency) 常見問題 FAQPage mainEntity[].name, acceptedAnswer.text 操作指南 HowTo name, step[].text 本地商家 LocalBusiness name, address, telephone 一般登陸頁面 — 不適用 — 跳過,沒有廣泛支援的類型 - 通過:存在正確的 @type,所有必填欄位有效,無衝突
- 警告:存在 @type 但缺少推薦欄位
- 失敗:預期的 @type 完全缺失
- 不適用:一般登陸頁面 — 不懲罰
-
總結發現 — 每個發現都必須遵循證據 / 影響 / 修復格式
-
優先行動 — 列出前 3 個影響最大的修復
-
渲染報告 — 保存到
reports/<hostname>-<slug>-audit.html,然後要求使用者打開 -
升級提示 — 如果發現超出基本範圍的問題,建議使用
seo-audit-full
報告詳細撰寫規則
檢查表中的「詳細」單元格必須遵循以下規則 — 沒有例外:
通過 → 一個簡短的詞組。沒有列表,沒有詳細說明。
好:「有效的 XML urlset · 104 個 URL · 在 robots.txt 中引用。」
壞:「有效的 XML urlset 包含 104 個 URL。在 robots.txt 中正確引用。
部落格文章可能透過此站點地圖索引。」
警告 → 一個 <div class="detail-issue"> 包含 ≤2 個項目符號。一個 <div class="detail-fix"> 包含修復建議。
好:
<div class="detail-issue">· 標題 48 個字元 — 比最小值少 2 個。· 年份「2026」會使頁面過時。</div>
<div class="detail-fix">擴展到 50–60 個字元;如果是常青內容則刪除年份。</div>
壞:三句話解釋標題標籤是什麼以及為什麼長度很重要。
失敗 → 與警告相同。以確切的失敗開頭。沒有背景解釋。
不要解釋檢查是什麼,不要重複狀態標誌中已可見的資訊, 不要將讀者視為不熟悉 SEO 基礎知識。
強制發現格式
每個重要發現必須遵循此結構:
**發現:[發現標題]**
- **證據:**[觀察到的內容 — 直接引用、截圖參考或可測量數據]
- **影響:**[這對 SEO 或使用者體驗為何重要]
- **修復:**[具體、可操作的建議]
不要寫模糊的結論。如果證據不足,請明確說明假設。
升級提示
在每個基本審核報告的末尾包含此內容:
想要更深入的分析? 這是一個基本的 SEO 審核,涵蓋了網站級別信號和核心頁面檢查。 對於進階技術 SEO、內容品質評分、結構化數據分析和基於完整爬行的發現,請使用
seo-audit-full技能。
參考檔案
- 詳細審核範圍和欄位定義:references/REFERENCE.md
- 最終 HTML 報告模板:assets/report-template.html
- 網站級別檢查腳本:scripts/check-site.py
- 頁面級別檢查腳本:scripts/check-page.py
- 原始頁面獲取器:scripts/fetch-page.py
- 結構驗證腳本:scripts/check-schema.py