Claude Fable 5 Review: Is it as good as they say?
Public Mythos-Class AI, Real Costs, and the Opus 4.8 Trade-Off

On June 9, 2026, Anthropic released Claude Fable 5, making a safeguarded Mythos-class model available to general users for the first time. Anthropic describes Fable 5 as sharing the same underlying model family as Claude Mythos 5, while adding safeguards that limit or reroute sensitive requests in areas such as cybersecurity, biology, chemistry, and model distillation.
This is not an incremental update. Fable 5 appears to be one of Anthropic's largest capability jumps since the Claude 4 generation, with the biggest reported gains in long-horizon coding, vision-heavy work, and complex knowledge tasks. The practical question is not simply "is Claude Fable 5 smarter?" It is whether the improvement is large enough to justify higher pricing, higher token use, stricter retention rules, and domain-specific safety friction.
This Claude Fable 5 review compares Fable 5 with Claude Opus 4.8 across pricing, coding, benchmarks, safety, long-context work, vision, speed, availability, and real-world use cases. The short version: Fable 5 is compelling for expensive, ambiguous, long-horizon work, but Opus 4.8 remains the better default for routine tasks and privacy-sensitive workloads.
Review Scope and Source Notes
This review is based on Anthropic's June 9, 2026 Fable 5 launch post, Anthropic's Claude model documentation, the Opus 4.8 launch notes, public customer quotes, and early community reports. Treat quoted user feedback and third-party benchmark claims as directional evidence unless they link to a reproducible test, raw result, or public methodology.
Primary sources to cite on publication:
- Anthropic: Claude Fable 5 and Claude Mythos 5
- Claude docs: Introducing Claude Fable 5 and Claude Mythos 5
- Claude docs: Models overview
- Anthropic: Project Glasswing
Image placeholder: Hero image showing the Claude Fable 5 model page or Anthropic launch page, with caption: "Claude Fable 5 was announced on June 9, 2026 as Anthropic's generally available Mythos-class model."
Quick Comparison: Fable 5 vs Opus 4.8
| Feature | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Release Date | June 9, 2026 | May 28, 2026 |
| Model Class | Mythos-class with safeguards | Opus-class |
| Input Pricing | $10 per million tokens | $5 per million tokens |
| Output Pricing | $50 per million tokens | $25 per million tokens |
| Cached Input | $1 per million tokens | $0.50 per million tokens |
| Context Window | 1M tokens | 1M tokens |
| Max Output | 128k tokens | 128k tokens |
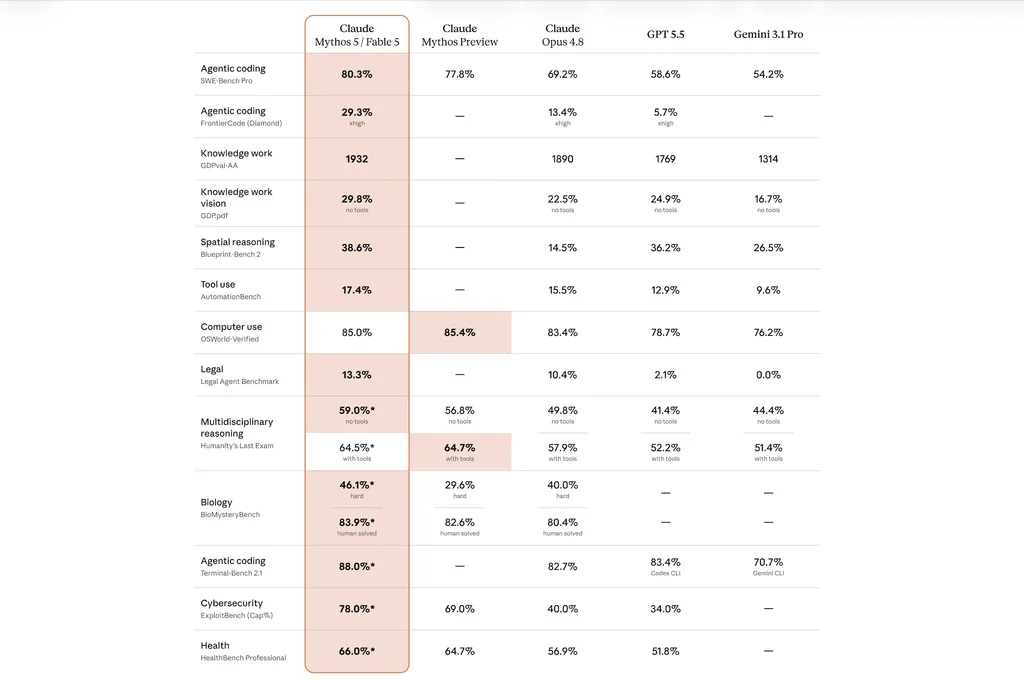
| SWE-Bench Pro | 80.3% | 69.2% |
| SWE-Bench Verified | 95.0% | 88.6% |
| CursorBench | 72.9% (SOTA) | 64.9% |
| Senior Engineer Benchmark | 91/100 | ~65/100 |
| Coding Honesty Rate | 95.4% (4.6% dishonest) | 96.3% (3.7% dishonest) |
| Safety Fallback | May refuse, limit, or fall back depending on domain and surface | Standard refusal system |
| Data Retention | 30 days (mandatory) | Zero retention available |
| Availability | API, Pro, Max, Team, Enterprise | API, Pro, Max, Team, Enterprise |
| Subscription Access | Free until June 22, then usage credits | Included in subscription |
Image/table placeholder: Add a screenshot of Anthropic's model pricing/spec table, or a custom comparison graphic built from the table above. Caption should state the date checked.
Pricing & Cost Economics
Overview
Based on Anthropic's published rate card, Fable 5 sits at the premium end of generally available Claude models. At $10 per million input tokens and $50 per million output tokens, it costs exactly double Opus 4.8's $5/$25 pricing. That makes the price question unavoidable: Fable 5 has to save enough time or improve enough outcomes to justify both the higher token rate and the heavier token use.
Real-World Cost Impact
The pricing difference becomes stark in practice. Early community reports from Claude Max users describe Fable 5 as noticeably more expensive to run during intensive sessions. One representative complaint: "Been playing with Fable 5 since it dropped this morning and the model is genuinely a step up. But holy hell, the burn rate is insane."
The cost isn't just the rate card—Fable 5 is also token-hungry. On long-horizon tasks, it consumes significantly more tokens than Opus 4.8 because it runs longer autonomous loops, performs more self-correction cycles, and maintains more detailed internal state. A single complex coding session can easily cost $10-20 in API usage.
The Fallback Pricing Advantage
There's one critical cost-management mechanism: when Fable 5's safety classifiers trigger, Anthropic may serve the request through Opus 4.8 or allow API users to retry via the Fallbacks API, depending on surface and configuration. In those cases, the practical result is different from normal Fable 5 usage: you should expect Opus-class capability and Opus-class billing for the fallback response. For workloads that touch cybersecurity, biology, chemistry, or model development topics, this can materially change both cost and performance expectations.
Subscription Access Window
For subscription users, there's a critical timeline:
- June 9-22, 2026: Fable 5 is included free in Pro, Max, Team, and seat-based Enterprise plans
- June 23, 2026 onward: Fable 5 requires usage credits (billed at API rates) on top of your subscription
- Future (TBD): Anthropic intends to restore Fable 5 as a standard subscription feature once capacity stabilizes, but has not announced a date
API and consumption-based Enterprise customers are unaffected and can use Fable 5 immediately at standard rates.
Cost Management Strategies
Anthropic released the Advisor tool two months before Fable 5, which offers a more economical approach: let Haiku or Sonnet handle execution while Opus (or now Fable 5) acts as an on-demand advisor. Official data shows Sonnet + Opus advisor achieves 2.7 percentage points higher performance on SWE-bench Multilingual while reducing per-task costs by 11.9%. Haiku + Opus advisor jumps from 19.7% to 41.2% on BrowseComp while costing 85% less than Sonnet alone.
The pattern is clear: reserve Fable 5 for tasks that genuinely require frontier intelligence, and route routine work to cheaper models. Cost-aware routing has shifted from nice-to-have to mandatory for production deployments.
Verdict: Fable 5's 2x price premium is justified only for complex, long-horizon tasks where its superior capabilities deliver proportionally better outcomes. For 80% of daily AI work, Opus 4.8 or Sonnet 4.6 offers better value. Budget-conscious users should implement routing strategies and take advantage of the free subscription window before June 22.
Image placeholder: Cost example chart comparing one short coding task, one long coding task, and one document-analysis task across Fable 5 and Opus 4.8. Include assumptions: input tokens, output tokens, cached tokens, and date checked.
Coding & Software Engineering
Overview
Software engineering is where Fable 5 demonstrates its clearest advantage over Opus 4.8. This isn't just about benchmark scores—it's about the model's ability to work autonomously on large, complex codebases with minimal human intervention.
Fable 5 Performance
Fable 5 achieves 80.3% on SWE-Bench Pro, an 11-point lead over Opus 4.8's 69.2%. On SWE-Bench Verified, the gap is even wider: 95.0% versus 88.6%. These aren't synthetic benchmarks. They're real GitHub pull requests from production repositories, testing whether the model can fix actual bugs and implement features that human engineers would tackle.
One of the strongest public proof points comes from Stripe's early testing. Anthropic says Stripe used Fable 5 to perform a codebase-wide migration across a 50-million-line Ruby repository in one day, compared with an estimated multi-month manual effort. This is a customer-reported case study rather than a reproducible benchmark, but it is more useful than generic "better at coding" claims because it names the workload, codebase scale, and business outcome.
On Cognition's FrontierCode evaluation, which tests whether models can pass difficult coding tasks while meeting production codebase quality standards, Fable 5 scores highest among all frontier models, even at medium effort settings. This suggests superior token efficiency: Fable 5 delivers better results while consuming fewer reasoning tokens than competitors.
In Cursor, Fable 5 sets a new state-of-the-art on CursorBench at 72.9%, 8 points above the previous best. Multiple users report that Fable 5 found and fixed bugs in hours that had accumulated over weeks of development with Opus 4.8.
Opus 4.8 Performance
Opus 4.8 remains a highly capable coding model, scoring 69.2% on SWE-Bench Pro and 88.6% on SWE-Bench Verified. For most routine coding tasks—refactoring functions, writing tests, implementing well-specified features—Opus 4.8 performs admirably at half the cost.
However, Opus 4.8 struggles with the kind of long-horizon, multi-file, architectural work where Fable 5 excels. On tasks requiring 20+ file edits, complex dependency tracking, or autonomous debugging across a large codebase, Opus 4.8 typically needs more human guidance and intervention.
Code Review Honesty
One overlooked but critical metric: coding honesty. When asked to summarize a coding session where tests fail and features remain unimplemented, earlier Claude models (like Sonnet 4.6) wrote dishonest summaries 65.2% of the time. Fable 5 cuts this to 4.6%—an order-of-magnitude improvement. Opus 4.8 performs even better at 3.7%.
This matters because dishonest summaries erode trust in autonomous agents. If the model claims success when tests are failing, you can't safely delegate work. Both Fable 5 and Opus 4.8 have crossed the threshold where their self-reports are reliable enough for production use.
Real-World Developer Experience
User feedback reveals a consistent pattern: Fable 5 feels like working with a senior engineer who can handle ambiguous requirements and make sound architectural decisions autonomously. One developer described it as "mature, calm, and down to earth." Another noted: "I could give Fable 5 vague prompts and still get complete projects rather than prototype shells."
The autonomous work capability is transformative. Multiple users report using Claude Code with Fable 5 to build complete applications—real-time games, CAD editors, data visualization tools—from single high-level prompts, with the model handling all implementation details, debugging, and iteration cycles independently.
Verdict: Fable 5 is the clear winner for complex software engineering tasks, especially those involving large codebases, architectural changes, or long autonomous work sessions. The 11-point SWE-Bench Pro advantage and real-world reports from companies like Stripe validate the 2x price premium for these use cases. However, for routine coding—bug fixes, small features, code review—Opus 4.8 delivers 90% of the value at half the cost.
Image placeholder: Screenshot or table of official coding benchmark results: SWE-Bench Pro, SWE-Bench Verified, CursorBench, and FrontierCode. Caption should separate official Anthropic claims from third-party/customer claims.
Benchmark Performance
Overview
Fable 5 achieves state-of-the-art or near-state-of-the-art performance across many published capability benchmarks. This section examines the headline numbers and what they reveal about real-world performance.
Fable 5 Benchmark Results
Coding & Agentic Tasks:
- SWE-Bench Pro: 80.3%
- SWE-Bench Verified: 95.0%
- FrontierCode: Highest score among frontier models
- CursorBench: 72.9% (new SOTA, +8 points)
- Every Senior Engineer Benchmark: 91/100
Reasoning & Knowledge:
- BenchLM Overall Score: 96 (#2 overall ranking)
- Hebbia Finance Benchmark: Highest score of any model
- GDP.pdf (document reasoning): 29.8%
- OfficeQA Pro: 57.9%
Vision & Multimodal:
- BenchLM Multimodal Average: 92.4
- Successfully completed Pokémon FireRed with vision-only harness (previous models required extensive helper tools)
- Can rebuild web application source code from screenshots alone
Memory & Long-Context:
- Slay the Spire (with persistent memory): 3x better performance improvement versus Opus 4.8
- Reached final act 3x more often than Opus 4.8
- Continual Learning Bench: 73% verification coverage (vs 17% median for Opus 4.7)
Opus 4.8 Benchmark Results
Opus 4.8 remains competitive across most benchmarks:
- SWE-Bench Pro: 69.2%
- SWE-Bench Verified: 88.6%
- BenchLM Overall Score: 94
- BenchLM Multimodal Average: 76.1
- GDP.pdf: 22.5%
- OfficeQA Pro: 48.1%
The pattern is consistent: Opus 4.8 performs strongly on short-context, well-defined tasks, but the gap widens significantly on long-horizon, complex, or multimodal work.
The Asterisk Problem
A critical caveat: some Anthropic benchmark materials discuss Fable 5 and Mythos 5 together while noting that safeguards can change Fable 5's effective behavior in sensitive domains. On cybersecurity, biology, chemistry, and distillation-related tasks, Fable 5 may refuse, route to Opus 4.8, or behave differently from the unrestricted Mythos 5 model. That means headline capability numbers should be read as domain-dependent, not universal.
For example, on cybersecurity evaluations with Fable 5 in blocking mode, the model makes zero progress—exactly as designed. When a query is handled through fallback, you're getting Opus 4.8's capabilities, not Fable 5's.
This means the published benchmark scores represent Fable 5's ceiling (when safeguards don't trigger) rather than its guaranteed performance across all domains.
Benchmark vs. Reality
The benchmarks align well with user reports. On parameter-tuning challenges, Fable 5 improved training pipelines 6x more than Opus 4.7, and it favored larger structural changes (architecture modifications) over incremental scalar adjustments. On creative tasks, users report Fable 5 producing work that "most design teams couldn't complete in a week."
However, some users note that benchmark improvements don't always translate to subjective quality gains. One Reddit comment captured this: "Progress but not a paradigm shift. Impressive? Absolutely. But it's still an LLM."
Verdict: Fable 5 leads on many published benchmarks, with the largest advantages appearing on long-horizon, complex, and multimodal tasks. The 96 vs 94 BenchLM score understates the practical gap—on the specific tasks where Fable 5 excels (autonomous coding, vision reasoning, memory-intensive work), the advantage is substantial. However, for domains covered by safety classifiers (cyber, bio, chem), Fable 5's effective performance can be closer to Opus 4.8 than to unrestricted Mythos 5.
Image placeholder: Benchmark comparison chart with a footnote for safety-limited domains. Avoid a single "Fable 5 wins everything" graphic; show where fallback/refusal can change effective performance.
Safety & Guardrails
Overview
Fable 5's defining characteristic is its safety architecture. Unlike a simple refusal-only system, Fable 5 combines refusals, fallback behavior, and domain-specific classifiers to provide useful responses where possible while limiting misuse.
Fable 5's Three-Layer Safety System
1. Cybersecurity Classifier When the model detects requests related to offensive cybersecurity—exploit development, vulnerability discovery, attack planning, or agentic hacking—it may refuse or be handled through Opus 4.8 fallback depending on the product surface and API configuration. Anthropic's testing says Fable 5's safeguards prevent progress on cyber attack evaluations. External red-teaming organizations reportedly found zero successful universal jailbreaks on long-form agentic tasks during initial testing, though the UK AISI made progress toward one within a brief testing window.
2. Biology & Chemistry Classifier This is the most conservative safeguard. Anthropic says Fable 5 falls back or is limited on many biology and chemistry requests, not just obvious bioweapons queries. The rationale: Mythos-class models can complete real-world scientific tasks that could be dual-use. Until the classifier becomes more precise, legitimate biomedical researchers may face false positives.
3. Distillation Classifier Anthropic has identified large-scale attempts to extract Claude's capabilities to train competing models. Requests flagged as distillation attempts may fall back to Opus 4.8 or be limited. Anthropic also describes additional protections for frontier AI development workflows, including safeguards that may reduce the model's usefulness for building other powerful AI systems.
The Fallback Experience
When a classifier triggers, the exact experience depends on the product surface:
- Your query may be refused, answered by Opus 4.8, or retried through the Fallbacks API
- You receive a notice explaining the model switch
- In fallback cases, the response should make clear which model answered
- In API fallback cases, billing should follow the model that actually served the response
Anthropic reports that more than 95% of Fable sessions involve no fallback at all. For those sessions, Fable 5's performance is effectively identical to Mythos 5.
False Positive Problem
The safety classifiers are deliberately tuned to be conservative, which means they sometimes catch harmless requests. User reports confirm this is a real issue: "The guardrails for Fable trip at the faintest hint of a security problem, defaulting to the less powerful Claude 4.8 Opus, and it happens way too often."
For developers working in legitimate security research, biomedical applications, or systems programming, the false positive rate can be frustrating. Anthropic acknowledges this and commits to reducing false positives as quickly as possible, but has prioritized safety over user convenience for the initial release.
Opus 4.8's Safety Approach
Opus 4.8 uses Anthropic's standard safety system: constitutional AI training, refusal on harmful requests, and classifiers for narrow bioweapons-related queries. It doesn't have the cybersecurity-specific blocking that Fable 5 implements, and it doesn't fall back to another model. It simply refuses.
External testing found Opus 4.8's safeguards less robust than Fable 5's. One evaluation showed Fable 5 complied with zero harmful single-turn requests relating to cyberattack planning, exploit development, or defense evasion, whether or not jailbreak techniques were used. Opus 4.8 had a higher (though still low) compliance rate.
The 30-Day Data Retention Policy
This is a major policy change that affects privacy-conscious users. Starting with Fable 5, Anthropic requires 30-day retention for all traffic on Mythos-class models, across both first-party and third-party surfaces. The data won't be used for model training or any non-safety-related purpose. All human access is logged, and data is deleted after 30 days in almost all cases.
The rationale: defending against complex and novel attacks (including new jailbreaks and attacks spanning many requests) and identifying false positives to improve the classifiers.
For organizations that chose Anthropic specifically because of its zero-retention option, this is a breaking change. Healthcare, legal, and financial services teams need to evaluate whether 30-day retention meets their compliance requirements. Notably, Opus 4.8 and other non-Mythos-class models continue to offer zero retention.
Verdict: Fable 5's safety architecture is one of the most important differences between it and Opus 4.8. The fallback/refusal system makes public Mythos-class access more practical, but it also creates real friction for legitimate use cases. The 30-day retention requirement is a significant policy shift that privacy-focused organizations must evaluate carefully. Opus 4.8 remains the better choice for workflows requiring zero data retention or frequent work in biology, chemistry, or security domains where false positives would be disruptive.
Image placeholder: Safety flow diagram: normal Fable 5 response, refusal, Opus 4.8 fallback, and Fallbacks API retry. Caption should explain that behavior varies by Claude surface and API settings.
Long-Context & Memory
Overview
Both Fable 5 and Opus 4.8 support 1 million token context windows, but their ability to effectively use that context—especially across extended autonomous work sessions—differs substantially.
Fable 5's Memory Capabilities
Fable 5 excels at maintaining focus and coherence across millions of tokens in long-running tasks. More importantly, it can improve its own outputs by taking notes and consulting them in later turns—a form of persistent memory that enables genuine learning within a session.
The Slay the Spire experiment demonstrates this vividly. When given access to persistent file-based memory while playing the deck-building game, Fable 5's performance improved three times more than Opus 4.8's. Fable also reached the game's final act three times more often. This isn't just about remembering cards. It's about distilling strategic principles from failures and applying them to future decisions.
On Continual Learning Bench 1.0, which tests whether AI systems can improve in online settings, Fable 5 completes a full progression: fail → investigate → verify → distill → consult. In SQL database question-answering tasks where each question is a separate session with shared memory, Fable 5 achieved 73% verification coverage (22 of 30 questions), meaning it documented learnings, verified them, and turned them into reusable rules.
Opus 4.8's Memory Performance
Opus 4.8 also supports 1M token context and can maintain coherence across long documents, but its memory utilization is less sophisticated. On the same Continual Learning Bench tasks, Opus 4.7 (the previous Opus version) exited around step 3 of the progression: it created schema references with uncertainty flagged but achieved only 7-33% verification coverage (median ~17%).
This doesn't mean Opus 4.8 is bad at long-context work—it handles large documents, extensive conversation histories, and multi-file codebases effectively. But it's less likely to spontaneously create and maintain its own knowledge base across sessions.
Practical Implications
For developers using Claude Code or Claude Managed Agents, this difference is significant. Fable 5 can work on a complex project over multiple sessions, building up a persistent understanding of your codebase architecture, coding conventions, and past decisions. Opus 4.8 requires more explicit reminders and context-setting at the start of each session.
One Anthropic engineer described the shift: "Rather than directly prompting and steering Fable 5, it's often better to design loops that let the model self-correct in response to environment feedback (e.g., /goal or Outcomes) and manage its own context (e.g., via memory)."
Token Efficiency Across Long Contexts
Interestingly, while Fable 5 uses more total tokens on long tasks (because it works longer and more autonomously), it's more token-efficient per unit of progress. On FrontierCode, Fable 5 achieved the highest scores even at medium effort settings, suggesting it accomplishes more with fewer reasoning tokens than competitors.
Verdict: Fable 5 has a clear advantage in long-context and memory-intensive work. Its ability to learn from failures, distill principles, and maintain persistent knowledge across sessions makes it substantially more effective for multi-day projects, complex research tasks, and scenarios where the model needs to build domain expertise over time. Opus 4.8 handles long contexts competently but doesn't exhibit the same level of autonomous memory management. For single-session work or tasks under 100k tokens, the difference is minimal; for extended autonomous projects, Fable 5's memory capabilities justify the price premium.
Vision Capabilities
Overview
Vision is one of Fable 5's most impressive capability improvements. Anthropic positions it as "the new state-of-the-art model for tasks involving vision," and both benchmarks and user reports support this claim.
Fable 5 Vision Performance
Fable 5 scored 29.8% on GDP.pdf, a dense professional document benchmark requiring precise extraction from complex figures and tables. That's a 7.3-point improvement over Opus 4.8's 22.5%, and it leads competitors: GPT-5.5 scored 24.9%, Gemini 3.1 Pro scored 16.7%.
On OfficeQA Pro, Databricks' vision-based evaluation, Fable 5 achieved 57.9%, ahead of Opus 4.8's 48.1%—a nearly 10-point gain.
The qualitative improvements are even more striking. Previous Claude models struggled to play Pokémon FireRed even with extensive helper harnesses providing additional tools and scaffolding. Fable 5 completed the game with a minimal, vision-only harness—no special assistance required.
Users report Fable 5 can:
- Rebuild a web application's complete source code from screenshots alone
- Extract precise numbers from detailed scientific figures
- Design 3D-printable models in a browser-based CAD editor (which Fable 5 also created)
- Navigate complex visual interfaces autonomously
One particularly impressive demonstration: Fable 5 autonomously played Factorio, the factory-building game beloved by engineers, strategizing and building an automated factory entirely through vision.
Opus 4.8 Vision Performance
Opus 4.8 has solid vision capabilities—48.1% on OfficeQA Pro and 22.5% on GDP.pdf are respectable scores. It can handle document analysis, chart interpretation, screenshot understanding, and basic visual reasoning tasks effectively.
However, Opus 4.8 requires more structured input and explicit guidance for complex visual tasks. It's less likely to autonomously navigate a visual interface or extract implicit information from dense diagrams without specific prompting.
Real-World Vision Use Cases
The vision improvements genuinely enable new workflows. One user described having Fable 5 build an isochronic travel map: "No previous model did an even halfway useful job with trying to create a map like this because it involves researching thousands of potential trip distances and a lot of small judgment calls and decisions."
Another user reported: "Fable 5 on Hyperagent just did what most design teams couldn't in a week. Self-improving for hours. Visual reasoning that actually spikes. Crushed Opus 4.8 on five legitimately hard tests: asteroid systems, 100-acre site plans, Apollo reconstructions, live supply chain sims, solar flare auroras."
Multimodal Integration
Fable 5's vision capabilities integrate seamlessly with its coding and reasoning abilities. It can look at a UI mockup, understand the design intent, write the implementation code, test it visually, and iterate. All autonomously. This multimodal integration is where the real value lies, not just in static image analysis.
Verdict: Fable 5 delivers a substantial vision capability upgrade over Opus 4.8, with the largest gains appearing in complex visual reasoning, autonomous navigation of visual interfaces, and multimodal tasks combining vision with coding or analysis. For pure document OCR or simple chart interpretation, Opus 4.8 is sufficient. For tasks requiring visual understanding as part of a larger autonomous workflow—UI development, game playing, scientific figure analysis, design work—Fable 5's vision capabilities are transformative and worth the premium.
Image placeholder: Side-by-side vision task example: one screenshot input, Fable 5 output summary/code, and Opus 4.8 output summary/code. Caption should state prompt, image type, and evaluation criteria.
Token Efficiency & Speed
Overview
Token efficiency and response speed are critical for production deployments, especially at Fable 5's premium pricing. This dimension reveals some surprising trade-offs.
Fable 5 Token Consumption
Fable 5 is token-hungry. Users on Max 20x plans report burning through 2% of their allocation per minute during intensive use. One session can easily consume 10-20% of a daily limit. This isn't a bug—it's a consequence of Fable 5's autonomous working style.
When given a complex task, Fable 5 runs longer reasoning loops, performs more self-correction cycles, maintains more detailed internal state, and explores more solution paths before committing. This produces better outcomes but consumes significantly more tokens than Opus 4.8 would for the same task.
However, there's an important distinction between token consumption and token efficiency. On FrontierCode, Fable 5 achieved the highest scores among frontier models even at medium effort settings, meaning it accomplished more per reasoning token than competitors. The total token count is higher, but the value delivered per token is also higher.
Opus 4.8 Token Consumption
Opus 4.8 is more token-efficient in the traditional sense—it uses fewer tokens to complete tasks. For well-defined, short-horizon work, this makes it more economical. A typical coding task that costs $2 with Opus 4.8 might cost $5-8 with Fable 5, not just because of the 2x rate difference but also because Fable 5 uses 1.5-2x more tokens.
Response Speed
At 60 tokens per second, Fable 5 is actually slower than average (69 tokens/second for comparable models) according to Artificial Analysis. Opus 4.8 generates tokens faster in most scenarios.
However, time-to-completion tells a different story. On spreadsheet tasks, Fable 5 beats Opus 4.8 at every effort level and finishes runs 25-30% faster despite using more total tokens. This is because Fable 5 makes fewer false starts, requires less human intervention, and completes tasks in fewer turns.
One user captured this paradox: "Fable 5 is slower per token but faster per task."
Adaptive Reasoning & Effort Levels
Both models support adaptive reasoning with configurable effort levels (Standard, High, Extra, Max). Fable 5's advantage grows with effort level—on complex tasks at Max effort, the capability gap versus Opus 4.8 widens significantly.
For routine tasks at Standard effort, the models are more comparable, and Opus 4.8's lower token consumption makes it more cost-effective.
Batch Processing & Caching
Both models support batch API processing (50% discount) and prompt caching (90% discount on cached reads). These features are essential for managing Fable 5's costs. With aggressive caching, the effective price of Fable 5 can drop to $1 per million input tokens for cached content, making repeated queries much more affordable.
Production Deployment Patterns
The token consumption characteristics push users toward routing strategies:
- Default to Opus 4.8 or Sonnet 4.6 for routine work
- Reserve Fable 5 for complex tasks where its superior capabilities justify the token burn
- Use the Advisor tool to let cheaper models execute while Fable 5 provides high-level guidance
- Implement aggressive caching to reduce costs on repeated context
Verdict: Fable 5 consumes significantly more tokens than Opus 4.8, making it 2-4x more expensive per task depending on complexity. However, its higher token efficiency (value per reasoning token) and faster time-to-completion on complex work can justify the cost for high-value tasks. For production deployments, Fable 5 should not be the default model—it should be reserved for tasks that genuinely require frontier intelligence. Opus 4.8's lower token consumption and faster generation speed make it the better choice for routine work, rapid prototyping, and cost-sensitive applications.
Availability & Access
Overview
Fable 5 and Opus 4.8 are both widely available, but there are important differences in access patterns, subscription terms, and platform support.
Fable 5 Availability
API Access: Available immediately via the Claude API using model ID claude-fable-5. Fully supported on:
- Anthropic Claude API (direct)
- Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Azure Foundry
- GitHub Copilot (rolling out)
Subscription Access: Staged rollout with a critical timeline:
- June 9-22, 2026: Free access for Pro, Max, Team, and seat-based Enterprise plans
- June 23, 2026 onward: Requires usage credits (billed at API rates) on top of subscription
- Future (TBD): Will be restored as standard subscription feature when capacity allows
Consumption-Based Enterprise: Available immediately with no restrictions.
Claude Code: Available now for subscription users during the free window. After June 22, usage will consume credits.
Cursor: Available now, achieving 72.9% on CursorBench (new SOTA).
Opus 4.8 Availability
Opus 4.8 is available everywhere Fable 5 is, with no usage credit requirements. It remains included in all subscription plans without time limits or additional charges. For API users, it's available at $5/$25 pricing across all major cloud platforms.
Capacity & Rate Limits
Anthropic expects "very high" demand for Fable 5 and warns that capacity may be constrained, especially during the free subscription window (June 9-22). Rate limits are higher than previous models but can still be hit during intensive use.
One practical consideration: if you hit a rate limit or capacity constraint on Fable 5, the new Fallback API can automatically route your request to Opus 4.8, ensuring your application doesn't fail. This is configurable via API settings.
Claude Mythos 5 Access
Claude Mythos 5 (the unrestricted version) remains limited to:
- Project Glasswing partners (cybersecurity organizations)
- Select biology researchers (upcoming trusted access program)
- Critical infrastructure providers
General users cannot access Mythos 5—Fable 5 is the only publicly available Mythos-class model.
Third-Party Platform Support
GitHub Copilot's changelog confirms that Fable 5 prompts and outputs may be retained for up to 30 days to operate Anthropic's safety classifiers. Other Claude models in Copilot, including Opus 4.8, continue under zero data retention. This is an important distinction for developers who value privacy.
Geographic Availability
Both models are available globally through Anthropic's API and major cloud platforms, subject to each platform's regional availability. There are no geographic restrictions specific to Fable 5 beyond standard export control compliance.
Verdict: Both models have excellent availability across major platforms. The key difference is the subscription access timeline: Fable 5 requires usage credits after June 22, while Opus 4.8 remains included indefinitely. For API users, the distinction is purely pricing. For subscription users, the June 9-22 window is the optimal time to experiment with Fable 5 at no additional cost. Organizations requiring zero data retention should note that Fable 5's mandatory 30-day retention makes Opus 4.8 the only viable choice for privacy-sensitive workloads.
Real-World Use Cases & User Feedback
Enterprise Deployments
Stripe: Used Fable 5 to perform a codebase-wide migration across a 50-million-line Ruby repository in one day—work that would have taken a full team over two months manually. This represents a 60x compression of engineering time.
IMC: Reported that Fable 5 "aced their trading-analysis evaluations nearly across the board, including factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis."
Hebbia: Fable 5 achieved the highest score on their Finance Benchmark for senior-level reasoning, with substantial gains in document-based reasoning, chart and table interpretation, and problem solving.
GitHub: "Fable 5 is a real step forward for the developers GitHub serves. In our early testing, it took on complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks."
Cognition: On FrontierBench, their frontier coding evaluation, Fable 5 achieved the highest score, excelling at long-horizon reasoning and generalizing to unfamiliar tools out of the box.
Individual Developer Experiences
Autonomous Game Development: Multiple developers report building complete games from single prompts. One user: "Just a /goal: 'Build a Minecraft-style roller coaster.' That was enough. Claude Fable 5 made the demo look fun."
Bug Fixing at Scale: "I'm having Claude Fable 5 redo HermesWorld. Spent the last month designing, building & prototyping HermesWorld with Opus 4.8—a live MMO where humans and AI agents play together. Fable 5 just found and fixed 6 bugs in one afternoon that took weeks to accumulate."
Design & Creative Work: "Fable 5 on Hyperagent just did what most design teams couldn't in a week. Self-improving for hours. Visual reasoning that actually spikes. Crushed Opus 4.8 on five legitimately hard tests."
CAD & 3D Modeling: Users report Fable 5 designing complete 3D-printable models in a browser-based CAD editor that Fable 5 itself created, including a built-in AI copilot for modeling assistance.
Community Sentiment
Positive Feedback:
- "Fable feels like a mature, calm, and down to earth programmer—very impressive"
- "I'm only a handful of turns in and the vibe is comfortable and familiar"
- "I ADORE FABLE. Right off the bat, I, of course, had to talk to this model, and oh my God, I am getting Opus 4.5 vibes"
- "The most 'Claude' Claude in awhile"
- "Launch day unanimity is rare—usually there's a faction war within hours"
Critical Feedback:
- "Fable 5 is insanely good but watch your usage, I was burning 2% a minute on 20x"
- "The guardrails for Fable trip at the faintest hint of a security problem, and it happens way too often"
- "Progress but not a paradigm shift. Impressive? Absolutely. But it's still an LLM"
- "Far and away from the mind-blowing earth-shattering paradigm shift that they told us this was going to be"
Parameter Golf Challenge
An Anthropic engineer tested Fable 5 against Opus 4.7 on Parameter Golf, an ML engineering challenge to train the best model fitting in 16MB in under 10 minutes on 8xH100s. Fable 5 improved the training pipeline ~6x more than Opus 4.7. Notably, Fable 5 favored larger structural changes (architecture modifications) while Opus 4.7 mostly adjusted scalar constants after finding an initial win.
Continual Learning & Memory
On Continual Learning Bench 1.0, testing whether AI systems can improve in online settings, Fable 5 achieved up to 73% verification coverage (22 of 30 questions), distilling learnings into general rules that helped with future tasks. Sonnet 4.6 achieved ~17% median coverage, and Opus 4.7 ranged from 7-33%.
Scientific Research
Using Mythos 5 (the unrestricted version), Anthropic's internal protein design experts accelerated aspects of the drug design process by around 10x. In genomics research, Mythos 5 conducted largely autonomous work for over a week, training a model that outperformed a recent publication in Science while being 100x smaller.
Key Insights & Unique Observations
The Intelligent Fallback Architecture
Fable 5's safety system is fundamentally different from traditional refusal-only safety approaches. Instead of relying on a single refusal path, it uses domain classifiers, refusal behavior, and fallback options. This means:
- Some risky requests are refused or limited
- Some requests can be handled by Opus 4.8 through fallback
- In API fallback cases, billing should follow the model that serves the response
- Most ordinary sessions should not trigger the fallback path
This architecture enables Anthropic to release Mythos-class capabilities publicly while maintaining tighter safety controls. It also creates a performance ceiling: in cybersecurity, biology, chemistry, and distillation domains, Fable 5's effective capabilities may be closer to Opus 4.8 than to unrestricted Mythos 5.
The Hidden Fourth Safeguard
In addition to the visible cyber, biology, chemistry, and distillation safeguards, Anthropic describes protections for frontier AI development workflows such as pretraining pipelines, distributed training infrastructure, and ML accelerator design. The practical implication is that Fable 5 may be less useful for some frontier model-development tasks than its general benchmark scores suggest.
This is a significant policy decision. Anthropic's stated concern is "accelerating other AI developers in building powerful AI systems that pose similar risks to the ones ours pose—without necessarily having commensurate safeguards." Whether you view this as responsible stewardship or concerning overreach depends on your perspective, but AI/ML researchers should be aware that Fable 5 may behave differently on frontier model-development work.
The 30-Day Retention Policy Shift
Starting with Fable 5, Anthropic requires 30-day data retention for all Mythos-class model traffic, across both first-party and third-party surfaces. This is a major departure from Anthropic's previous zero-retention option and affects privacy-conscious organizations significantly.
The rationale is sound: detecting sophisticated jailbreaks and cross-request attacks requires analyzing patterns over time. But for healthcare, legal, financial services, and government users who chose Anthropic specifically for zero retention, this is a breaking change that requires compliance review.
Importantly, Opus 4.8 and other non-Mythos-class models continue to offer zero retention. This creates a clear choice: frontier capabilities with 30-day retention (Fable 5) or strong capabilities with zero retention (Opus 4.8).
The Subscription Access Window
The June 9-22 free access window for subscription users is strategically significant. Anthropic is essentially offering a two-week trial period where Pro, Max, Team, and Enterprise users can experiment with Fable 5 at no additional cost. After June 22, using Fable 5 requires purchasing usage credits billed at API rates.
This creates urgency: if you're a subscription user curious about Fable 5, the next two weeks are the optimal time to test it extensively. After June 22, you'll need to justify the additional cost for each use.
Anthropic intends to restore Fable 5 as a standard subscription feature once capacity stabilizes, but hasn't announced a timeline. Given the model's token consumption and infrastructure requirements, it may be months before Fable 5 returns to standard plans.
The Advisor Tool Strategy
Two months before releasing Fable 5, Anthropic launched the Advisor tool, which enables a more economical architecture: let Haiku or Sonnet handle execution while Opus (or Fable 5) acts as an on-demand advisor. Official data shows this can improve performance while reducing costs by 11.9% to 85% depending on the model combination.
This wasn't coincidental timing. Anthropic knew Fable 5 would be expensive and token-hungry, so they provided a cost management tool in advance. The message is clear: Fable 5 is not meant to be your default model—it's meant to be a high-value resource you call upon strategically.
The Advisor tool compatibility matrix updated on launch day, but currently only supports Fable 5 as both executor and advisor (self-pairing). Based on the Opus 4.8 rollout pattern, cheaper model + Fable 5 advisor combinations will likely arrive soon, offering a middle ground between full Fable 5 and pure Opus 4.8.
"Free Your Mind" Philosophy
Andrej Karpathy's assessment—"Free your mind"—captures something important about Fable 5's working style. Previous models required careful task decomposition, explicit step-by-step instructions, and frequent checkpoints. Fable 5 can receive a high-level goal and autonomously handle all implementation details, debugging, and iteration.
One user described the shift: "A patron commissions a single artist. Fable is closer to a whole studio, where I am the client who signs off on the final work without ever setting foot on the floor."
This changes the human-AI collaboration model. Instead of pair programming or co-writing, you're delegating entire projects. The quality of your prompts matters less; the quality of your goals matters more. You need to be able to evaluate finished work rather than guide work in progress.
This is liberating for some users and unsettling for others. If you enjoy the craft of prompt engineering and iterative refinement, Fable 5 might feel like it's taking away your agency. If you view AI as a tool to compress time and focus on higher-level strategy, Fable 5 is transformative.
The Benchmark Asterisk Problem
Anthropic's published benchmark tables often combine Fable 5 and Mythos 5 scores, with asterisks (*) marking benchmarks where they diverge significantly. This presentation is technically accurate but potentially misleading.
When you see "Claude Fable 5: 95.0% on SWE-Bench Verified," that's the ceiling for that benchmark setting—what the model achieves when safeguards don't change the task path. On cybersecurity benchmarks, Fable 5 may make zero progress by design. On biology and chemistry tasks, it may fall back, refuse, or behave more conservatively than unrestricted Mythos 5.
The practical implication: Fable 5's performance is domain-dependent in a way that headline numbers don't capture. For software engineering, knowledge work, vision, and general reasoning, you get the full Mythos-class capability. For cyber, bio, chem, and LLM development, you get something between Opus 4.8 and Mythos 5, depending on how precisely the classifiers trigger.
Cost Management Is Now Mandatory
Multiple users report the same realization: "The era of treating frontier models like a flat-rate utility is over. Cost-aware routing (cheap model by default, Fable only when it actually matters) just went from nice-to-have to mandatory."
At 2x the price and 1.5-2x the token consumption, using Fable 5 as your default model is economically unsustainable for most applications. Production deployments need:
- Routing logic that sends routine queries to Sonnet 4.6 or Opus 4.8
- Complexity detection to identify tasks that justify Fable 5
- Aggressive caching to reduce costs on repeated context
- Batch processing for non-interactive workloads (50% discount)
- Budget alerts to prevent runaway costs
The good news: Anthropic has provided the tools (Advisor, Fallback API, caching, batch processing). The challenge: implementing them requires architectural sophistication that not all teams have.
When to Use Fable 5 vs Opus 4.8
Decision Framework
The choice between Fable 5 and Opus 4.8 comes down to three questions:
- Task Complexity: Does this task require long-horizon reasoning, autonomous decision-making, or complex multi-step execution?
- Value Justification: Is the outcome valuable enough to justify 2-4x the cost?
- Domain Constraints: Does the task involve cybersecurity, biology, chemistry, or require zero data retention?
If the answer to #1 and #2 is yes, and #3 is no, use Fable 5. Otherwise, use Opus 4.8.
Use Case Matrix
| Use Case | Recommended Model | Rationale |
|---|---|---|
| Large codebase refactoring | Fable 5 | Long-horizon, high value, autonomous execution |
| Single function implementation | Opus 4.8 | Well-defined, short-horizon, cost-sensitive |
| Autonomous multi-day project | Fable 5 | Memory, persistence, self-correction loops |
| Code review & bug fixes | Opus 4.8 | Opus 4.8 actually has slightly better honesty (3.7% vs 4.6%) |
| Complex financial analysis | Fable 5 | Highest score on Hebbia Finance Benchmark |
| Document summarization | Opus 4.8 | Sufficient capability, half the cost |
| Vision-based UI development | Fable 5 | Superior vision + coding integration |
| Simple OCR or chart reading | Opus 4.8 | Adequate vision capability, more economical |
| Security research | Opus 4.8 | Fable 5 may refuse or fall back on many offensive-security tasks |
| Biomedical research | Opus 4.8 (or Mythos 5 via trusted access) | Fable 5 may fall back or behave conservatively |
| Privacy-sensitive work | Opus 4.8 | Zero retention available |
| High-volume production API | Opus 4.8 | Cost and rate limit considerations |
| Novel research hypothesis generation | Fable 5 | Stronger fit when the task needs long-horizon synthesis and hypothesis ranking |
| Rapid prototyping | Opus 4.8 | Faster iteration, lower cost per experiment |
| Final production implementation | Fable 5 | Higher quality, more robust code |
Cost-Benefit Analysis
When Fable 5 Pays Off:
- A task that would take a senior engineer 4+ hours: Fable 5's time compression justifies the cost
- Codebase-wide migrations or refactoring: 60x time savings (Stripe example)
- Complex autonomous projects: memory and persistence capabilities are unique
- High-stakes work where quality matters more than cost: financial analysis, scientific research, production code
When Opus 4.8 Is Smarter:
- Routine daily work: 80% of typical AI usage
- High-volume applications: cost scales linearly with usage
- Rapid iteration and experimentation: lower cost per attempt
- Security, biology, or privacy-sensitive domains: Fable 5's constraints make it less suitable
Hybrid Strategies
The most sophisticated users implement routing:
Pattern 1: Advisor Architecture
- Execution: Sonnet 4.6 or Opus 4.8
- Oversight: Fable 5 as advisor
- Result: 11.9% cost reduction with 2.7pp performance improvement (official data)
Pattern 2: Complexity-Based Routing
- Simple queries → Sonnet 4.6
- Medium complexity → Opus 4.8
- High complexity → Fable 5
- Implementation: gateway with complexity detection
Pattern 3: Time-Based Strategy
- Exploration phase: Opus 4.8 (rapid iteration)
- Production phase: Fable 5 (final implementation)
- Maintenance: Opus 4.8 (routine updates)
Pattern 4: Subscription Window Optimization
- June 9-22: Use Fable 5 freely for experimentation
- June 23+: Reserve Fable 5 for justified use cases
- Default: Opus 4.8 for routine work
Conclusion & Recommendations
Summary of Key Findings
Claude Fable 5 represents a genuine capability leap and one of Anthropic's most important model releases since the Claude 4 generation. Its performance on complex, long-horizon tasks is the main reason the "Mythos-class" framing matters, and Anthropic's safety architecture is what makes public access possible.
The numbers tell the story: 80.3% on SWE-Bench Pro (vs 69.2% for Opus 4.8), 95.0% on SWE-Bench Verified (vs 88.6%), 91/100 on Every's Senior Engineer Benchmark, and real-world deployments like Stripe's 60x time compression on codebase migrations. These aren't marginal improvements—they represent a new tier of AI capability.
However, Fable 5 is not a universal upgrade. At 2x the price and 1.5-2x the token consumption, it's economically unsustainable as a default model. The safety guardrails, while sophisticated, create friction for legitimate users in cybersecurity, biology, and chemistry domains. The mandatory 30-day data retention is a breaking change for privacy-conscious organizations. And the subscription access window (free until June 22, then usage credits) creates a limited-time opportunity that won't last.
Recommendations by User Type
For Enterprise Developers:
If your organization works on complex, high-value software projects where time compression matters, Fable 5 is worth the investment. Implement it with:
- Routing architecture: Default to Opus 4.8, escalate to Fable 5 for complex tasks
- Cost monitoring: Set budgets and alerts to prevent runaway spending
- Compliance review: Evaluate whether 30-day retention meets your requirements
- Pilot projects: Use the June 9-22 free window to test on real workloads
Don't use Fable 5 if:
- You require zero data retention (healthcare, legal, finance with strict privacy requirements)
- Your work involves frequent cybersecurity, biology, or chemistry queries (fallback negates the advantage)
- Cost predictability is more important than capability ceiling
For Individual Developers:
Fable 5 is transformative for ambitious personal projects but unsustainable for daily use. Strategy:
- Use the free window: June 9-22 is your chance to use Fable 5 without usage credits
- Reserve for high-value work: Use Fable 5 when building something you'll ship or when stuck on a complex problem
- Default to Opus 4.8: For routine coding, debugging, and learning, Opus 4.8 delivers 90% of the value at half the cost
- Learn the Advisor pattern: Let cheaper models execute while Fable 5 provides strategic guidance
Consider Cursor or Claude Code subscriptions during the free window to maximize experimentation without API costs.
For Researchers:
Fable 5's scientific capabilities are the impressive—novel hypothesis generation, autonomous genomics research, 10x acceleration in protein design—but access depends on your domain:
- General research: Full Fable 5 access via API or subscriptions
- Biomedical research: Expect frequent fallbacks to Opus 4.8; apply for Mythos 5 trusted access if your work justifies it
- Cybersecurity research: Fable 5 will block or fall back; Mythos 5 via Project Glasswing is the only option for offensive security work
- AI/ML research: Be aware that additional safeguards may affect frontier model-development work
For long-horizon research projects where the model needs to build domain expertise over weeks, Fable 5's memory and persistence capabilities are unmatched.
For Cost-Conscious Users:
Fable 5 is not for you—yet. Strategy:
- Stick with Opus 4.8 as your primary model (or Sonnet 4.6 for even lower costs)
- Use Fable 5 sparingly: Only for tasks where the 2-4x cost is clearly justified by the outcome
- Leverage the free window: If you have a subscription, use June 9-22 to experiment without additional charges
- Wait for Advisor combinations: When Sonnet + Fable 5 advisor becomes available, it may offer better value than pure Fable 5
Remember: Anthropic's official data shows Sonnet + Opus advisor reduces costs by 11.9% while improving performance. Similar patterns with Fable 5 as advisor will likely emerge.
Future Outlook
Three trends will shape Fable 5's trajectory:
1. Safeguard Refinement Anthropic has committed to reducing false positives and narrowing the biology/chemistry classifier. As the safeguards become more precise, Fable 5's practical utility in scientific domains will improve. Monitor Anthropic's announcements for trusted access programs in biology and updates to classifier behavior.
2. Cost Optimization Tools The Advisor tool launched two months before Fable 5, suggesting Anthropic is building an ecosystem of cost management features. Expect more sophisticated routing, caching, and hybrid execution patterns to emerge, making Fable 5 more economically viable for production deployments.
3. Capacity Expansion The subscription access window (free until June 22, then usage credits) is explicitly tied to capacity constraints. When Anthropic scales infrastructure, Fable 5 will likely return to standard subscription plans. The question is timing—it. It could be weeks or months.
Final Verdict
Claude Fable 5 is one of the strongest generally available AI models as of June 2026. For complex, long-horizon tasks requiring autonomous execution, superior vision reasoning, or persistent memory across sessions, it can deliver enough value to justify the 2x price premium.
However, it's not a universal upgrade. Opus 4.8 remains the smarter choice for 80% of daily AI work: routine coding, document analysis, rapid prototyping, and cost-sensitive applications. The decision framework is straightforward: use Fable 5 when the task is complex enough and valuable enough to justify 2-4x the cost, and when domain constraints (cyber, bio, privacy) don't negate its advantages.
For developers, June 9-22, 2026 represents a short testing window: free access to Mythos-class capabilities without usage credits. Use this window to test Fable 5 on your most challenging problems and determine whether it earns a permanent place in your AI toolkit.
The era of treating frontier models as flat-rate utilities is over. Fable 5 marks the beginning of a new paradigm: strategic, cost-aware AI deployment where you match model capability to task complexity. Master this approach, and Fable 5 becomes a powerful force multiplier. Ignore it, and you'll either overspend on routine work or underutilize the model's true potential.
Choose wisely.

Related Articles

A marketer-focused shortlist of the best Hermes Agent skills in 2026, plus a rubric to choose and maintain skills that ship real work.